
|
I am a Research Engineer at Apple, where I develop multimodal generative models for Apple Intelligence. My work focuses on Apple's Diffusion Models that power image generation and editing experiences, including Image Playground and Genmoji. Prior to this, I received my Ph.D. from University of California, Merced, under the supervision of Prof. Ming-Hsuan Yang in the Vision and Learning Lab. I completed my M.S. in Computer Science from The University of Texas at Austin and my B.S. in Electrical Engineering from National Taiwan University. My research interests lie in computer vision and machine learning, with a focus on image, video and 3D generation and manipulation. I am fortunate to intern at Google with Deqing Sun, Yu-Chuan Su, Hexiang Hu, Lu Jiang, Charles Herrmann, Yaojie Liu, and Xinyi Wang, at Adobe Research with Zhan Xu and Yang Zhou, and to receive advice from Hung-Yu Tseng and Jia-Bin Huang. I am honored to be a finalist for the Meta PhD Research Fellowship. Email / CV / Google Scholar / LinkedIn / GitHub |
|







|
|

|
Hsin-Ping Huang, Xinyi Wang, Yonatan Bitton, Hagai Taitelbaum, Gaurav Singh Tomar, Ming-Wei Chang, Xuhui Jia, Kelvin C.K. Chan, Hexiang Hu, Yu-Chuan Su, Ming-Hsuan Yang TMLR 2026 KITTEN is a benchmark for evaluating text-to-image models' ability to generate real-world visual entities, highlighting that even advanced models struggle with entity fidelity. Project Page / Paper |
|
|
Hsin-Ping Huang, Yang Zhou, Jui-Hsien Wang, Difan Liu, Feng Liu, Ming-Hsuan Yang, Zhan Xu CVPR 2025 Move-in-2D generates human motion sequences conditioned on a scene image and text prompt, using a diffusion model trained on a large-scale dataset of annotated human motions. Project Page / Paper |
|
|
Hsin-Ping Huang, Yu-Chuan Su, Deqing Sun, Lu Jiang, Xuhui Jia, Yukun Zhu, Ming-Hsuan Yang WACV 2025 FACTOR is a video generation model that allows detailed control over objects' appearances, context, and location by optimizing the inserted attention layer with large-scale annotations. Project Page / Paper / Media (AK) |

|
Hsin-Ping Huang, Yu-Chuan Su, Ming-Hsuan Yang WACV 2025 We propose a framework for generating long-take videos with multiple coherent events by decoupling video generation into keyframe generation and frame interpolation. Paper / Media (AK) |

|
Hsin-Ping Huang, Charles Herrmann, Junhwa Hur, Erika Lu, Kyle Sargent, Austin Stone, Ming-Hsuan Yang, Deqing Sun CVPR 2023 Self-supervised AutoFlow is a framework for learning optical flow training datasets that replaces the need for ground truth labels by using a self-supervised loss as the search metric. Project Page / Paper |

|
Hsin-Ping Huang, Deqing Sun, Yaojie Liu, Wen-Sheng Chu, Taihong Xiao, Jinwei Yuan, Hartwig Adam, Ming-Hsuan Yang ECCV 2022 We present adaptive vision transformers for face anti-spoofing, introducing ensemble adapters and feature-wise transformation layers for domain adaptation with few samples. Project Page / Paper |
|
|
Hsin-Ping Huang, Hung-Yu Tseng, Saurabh Saini, Maneesh Singh, Ming-Hsuan Yang ICCV 2021 We tackle 3D scene stylization, generating stylized images from novel views by constructing a point cloud, aggregating style statistics, and modulating features with a linear transformation. Project Page / Paper / Media (AK) |
|
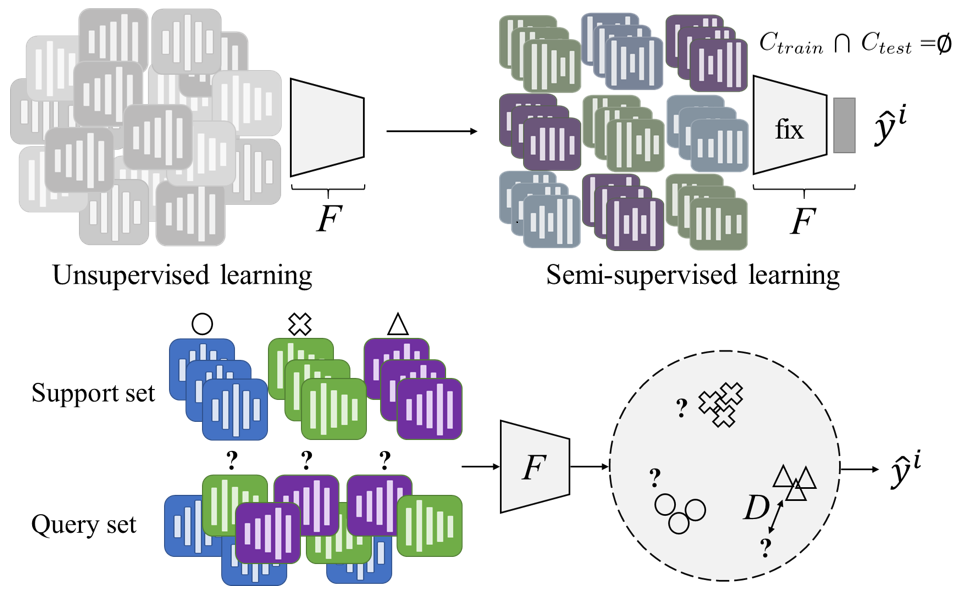
Hsin-Ping Huang, Krishna C. Puvvada, Ming Sun, Chao Wang ICASSP 2021 We study semi-supervised few-shot acoustic event classification, learning audio representations from a large amount of unlabeled data and using these representations for classification. Paper |
|
|
Hsin-Ping Huang, Hung-Yu Tseng, Hsin-Ying Lee, Jia-Bin Huang ECCV 2020 We address semantic view synthesis: generating free-viewpoint renderings of a synthesized scene from a semantic label map by synthesizing a multiple-plane image (MPI) representation. Project Page / Paper / Media (AK) |
|
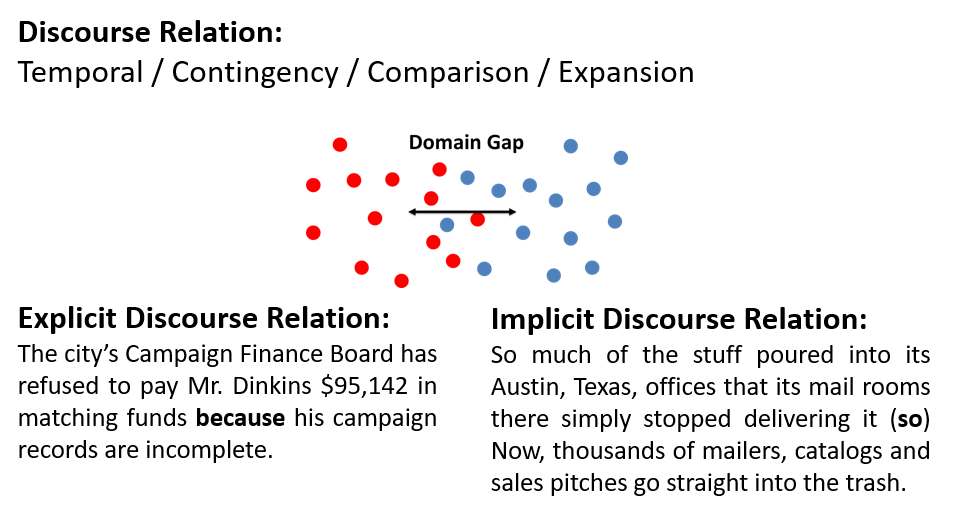
Hsin-Ping Huang, Junyi Jessy Li CoNLL 2019 We present an unsupervised adversarial domain adaptive network with a reconstruction component that leverages explicit discourse relations to classify implicit discourse relations. Paper |
|
UC Merced Bobcat Fellowship, 2024 Meta PhD Research Fellowship Finalist - AR/VR Human Understanding, 2022 |
|
Area Chair: NeurIPS'26 Journal Reviewer: TPAMI, IJCV, TIP, Computer Graphics Forum, SPL Conference Reviewer: CVPR'22,'23,'25, ICCV'21,'23,'25, ECCV'22,'24, NeurIPS'24,'25, ICLR'25,'26, WACV'25, ACCV'24, AAAI'23,'24,'25,'26, IJCAI'23,'24 |
|
This page borrows designs from Jon Barron's website. |
